主页 > imtoken钱包地址转账查询 > 【爬虫】使用Python爬取非小网站数字货币(一)_Kandy
【爬虫】使用Python爬取非小网站数字货币(一)_Kandy
一、环境
环境搭建,自百度
二、本节内容说明
本栏目主要采集非小账户所包含的所有数字货币的详细链接和数字货币名称。
三、数据库说明1.货币详情页面链接
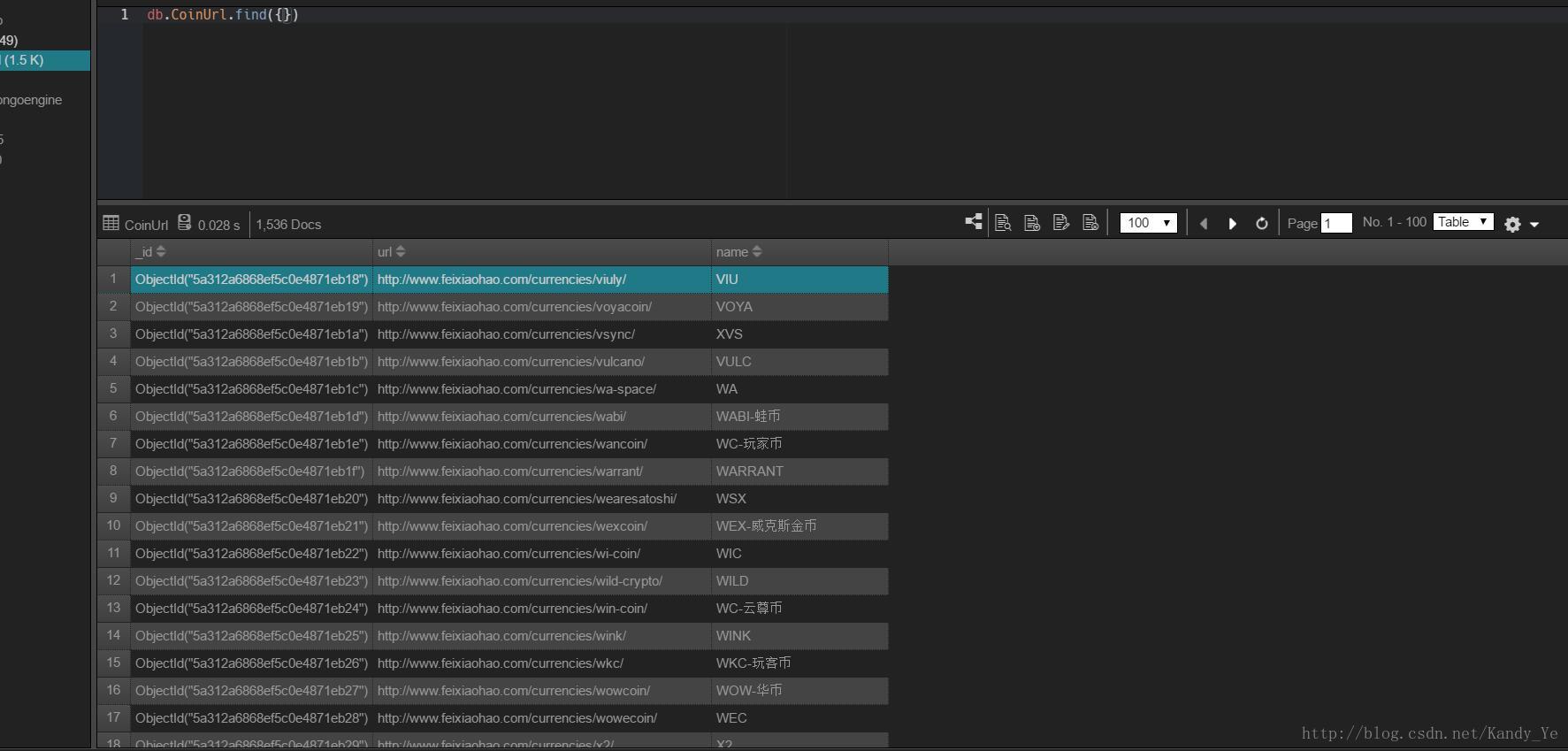
飞晓包含1536种数字货币的信息:
http://www.feixiaohao.com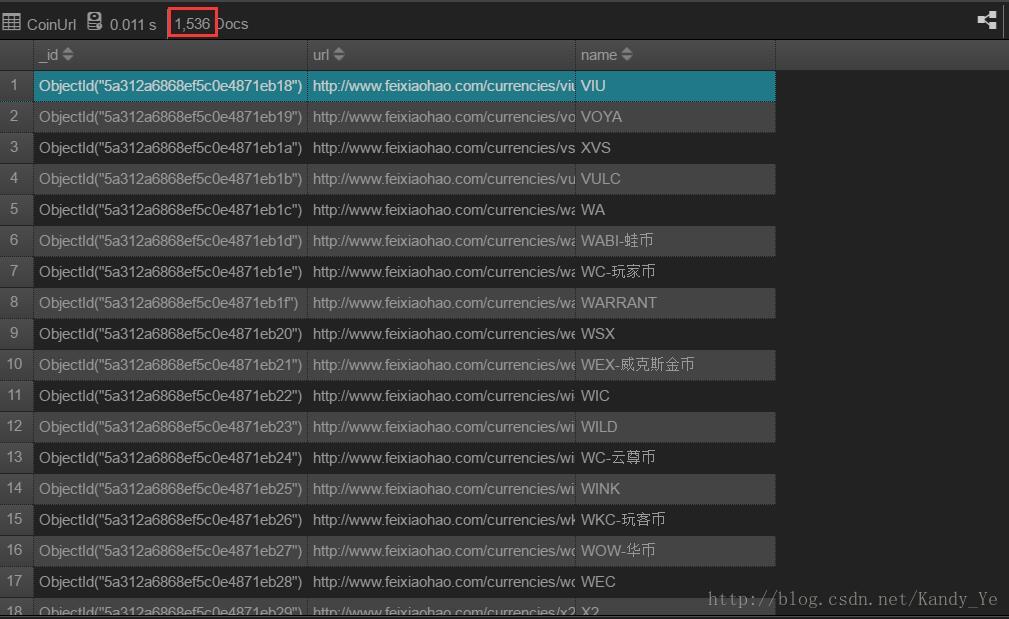
为了准备后面抓取详细信息非小号数据查询,我们需要先抓取详细页面的地址,所以我们只需要数字货币的链接地址的数据库设计的币名和对应的URL,然后ID。如下:
name #分类名称
url #分类url
_id #分类id
四、获取指令
由于非小网站提供了在首页展示所有数字货币的功能,我们就不用逐页爬取,偷懒了:
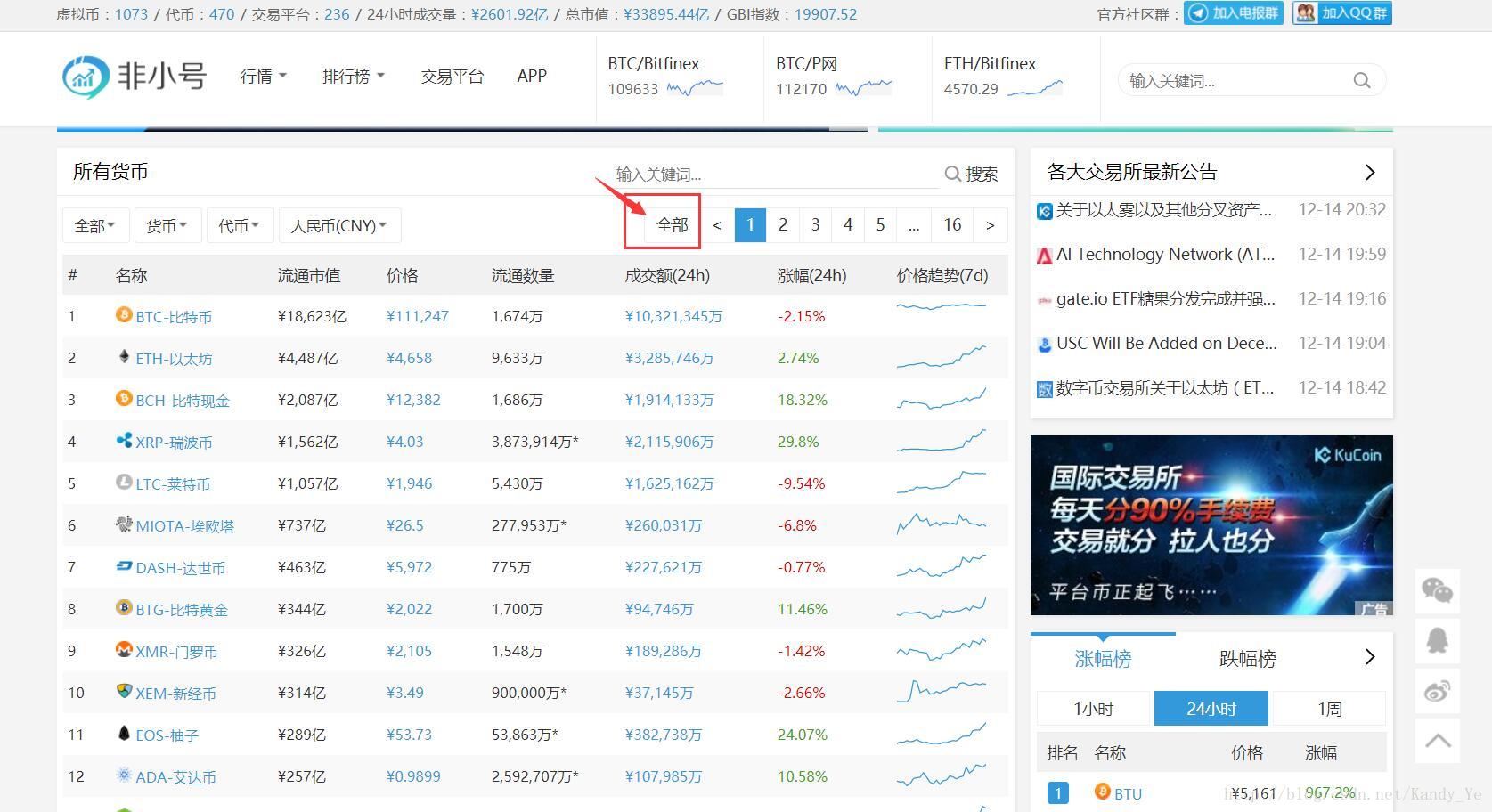
后续爬取直接使用显示所有硬币的链接:
http://www.feixiaohao.com/all/1. 新项目
在您的工作目录中创建一个新的 scrapy 项目并使用以下命令:
scrapy startproject coins目录结构如下:

coins/
scrapy.cfg
coins/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
...2. 设置使用mongodb存储数据
将以下信息添加到设置文件:
ITEM_PIPELINES = {
"CoinSpider.pipelines.MongoDBPipeline": 403,
}3. MongoDB 管道定义
将以下类添加到 pipelines.py 文件中:
class MongoDBPipeline(object):
def __init__(self):
clinet = pymongo.MongoClient("localhost", 27017)
db = clinet["Coins"]
self.CoinUrl = db["CoinUrl"]
def process_item(self, item, spider):
""" 判断item的类型,并作相应的处理,再入数据库 """
if isinstance(item, CoinUrl):
try:
count = self.CoinUrl.find({
'name': item['name']}).count()
if count > 0:
self.CoinUrl.update({
'name': item['name']}, dict(item))
else:
self.CoinUrl.insert(dict(item))
except Exception as e:
print(e)
pass为了防止数据被重复写入,需要在写入数据之前判断相应的信息是否已经存入数据库。如果已经存储,则更新相应的信息非小号数据查询,如果没有,直接插入。
4. 创建数据库

在items.py文件中新建一个Document类,和我们之前设计的数据库是一致的。相关代码如下:
import scrapy
class CoinUrl(scrapy.Item):
_id = scrapy.Field()
url = scrapy.Field()
name = scrapy.Field()5. 创建爬虫文件
在spiders目录下新建一个python文件,命令为CoinSpider.py,作为我们的爬虫文件,在文件中新建一个CoinSpider类,继承自Spider。并且需要定义以下三个属性:
相关代码如下:
import re
import json
import time
import requests
import logging
from scrapy import Spider, Selector
from scrapy.http import Request
from CoinSpider.items import *
class CoinSpider(Spider):
name = 'CoinSpider'
allowed_domains = ['feixiaohao.com']
start_urls = [
'http://www.feixiaohao.com/all/'
]
logging.getLogger("requests").setLevel(logging.WARNING) # 将requests的日志级别设成WARNING
tool = Tool()
def start_requests(self):
for url in self.start_urls:
yield Request(url=url, callback=self.parse_coin)6. 页面分析
查看页面上的信息,可以发现所有的数字货币信息都在一个表格中:
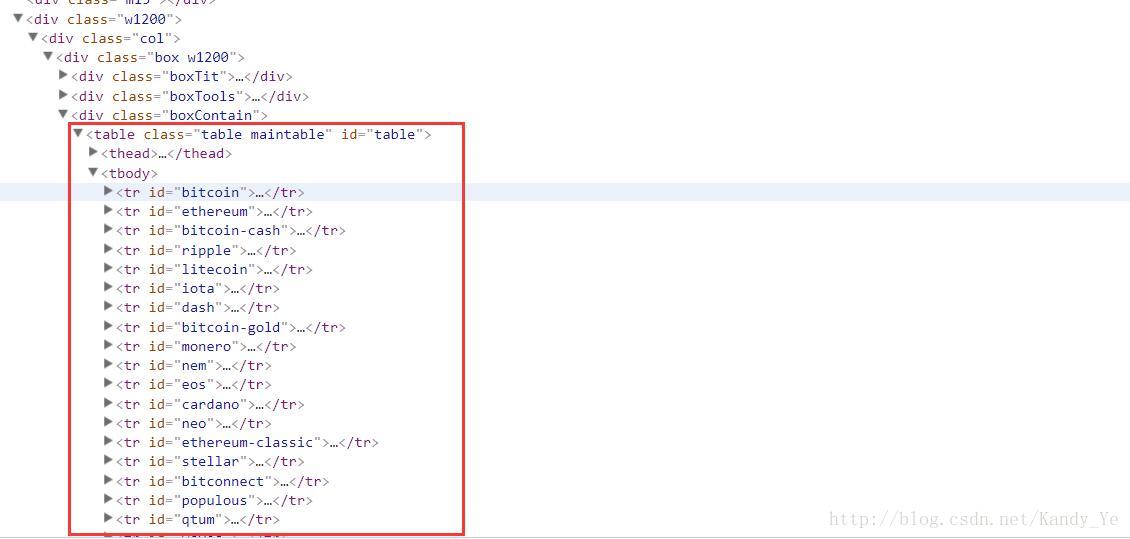

每个数字货币的详细地址和名称都在它的第一个标签中:
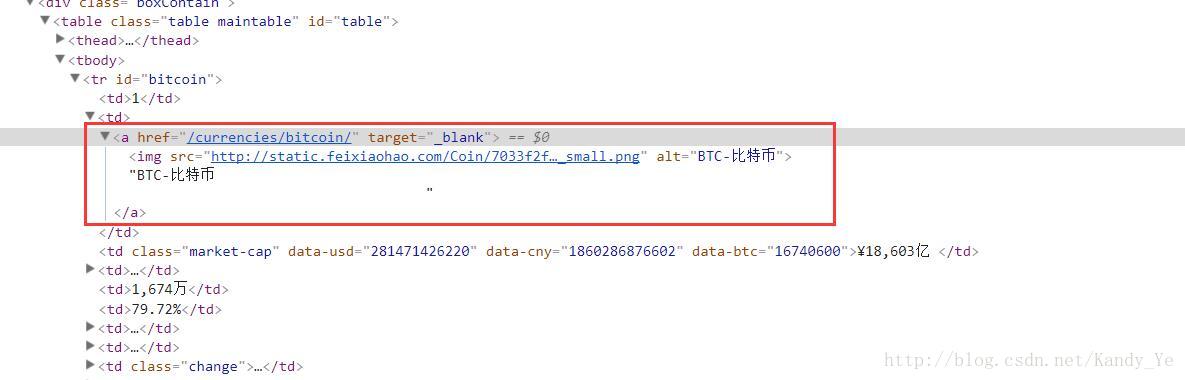
所以我们只需要先抓取各个数字货币的a标签的内容,通过选择器的xpath定位即可:
'//div[@class="boxContain"]/table/tbody/tr/td/a'获取a标签的所有内容,注意获取的结果是一个列表。
而我们需要的是详细信息的地址和名称在a标签的链接和img子标签的alt值中:

所以我们通过正则表达式来提取它:
r'.*? alt="(.*?)">'
由于是多行提取,所以需要在代码中添加re.S项,具体见下面代码。
从页面元素可以知道,除了每个数字货币的Item下面我们需要成为a之外,还有很多其他的信息也放在了a标签中:
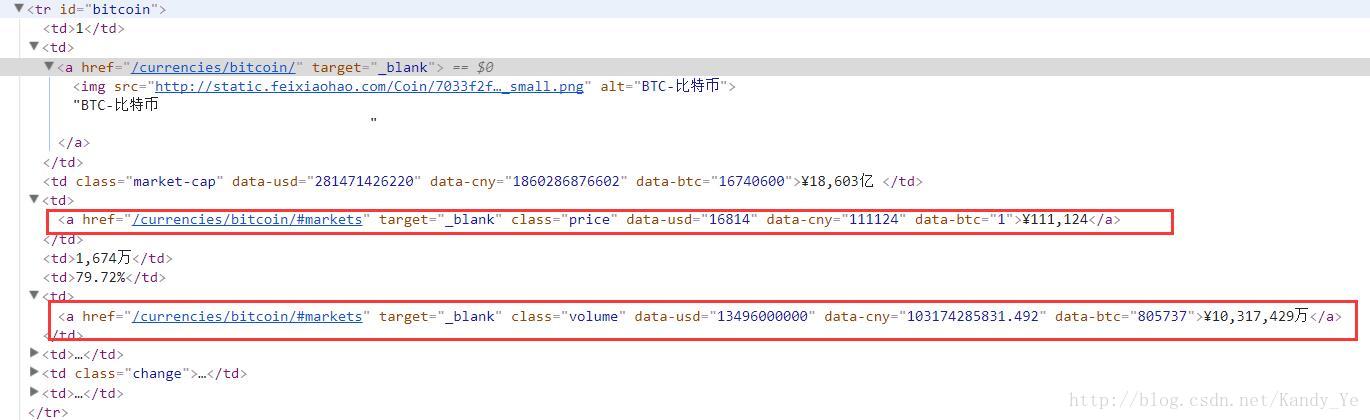
而这些a标签显然不符合我们上面用来提取信息的正则表达式,所以通过上面的正则表达式,得到的信息是空的,我们只需要过滤这部分信息。
详细代码如下:
selector = Selector(response)
items = selector.xpath('//div[@class="boxContain"]/table/tbody/tr/td/a').extract()
for item in items:
urls = re.findall(r'.*? alt="(.*?)">', item, re.S)
if len(urls) > 0:
print(urls[0][0])
print(urls[0][1])7. 爬取过程
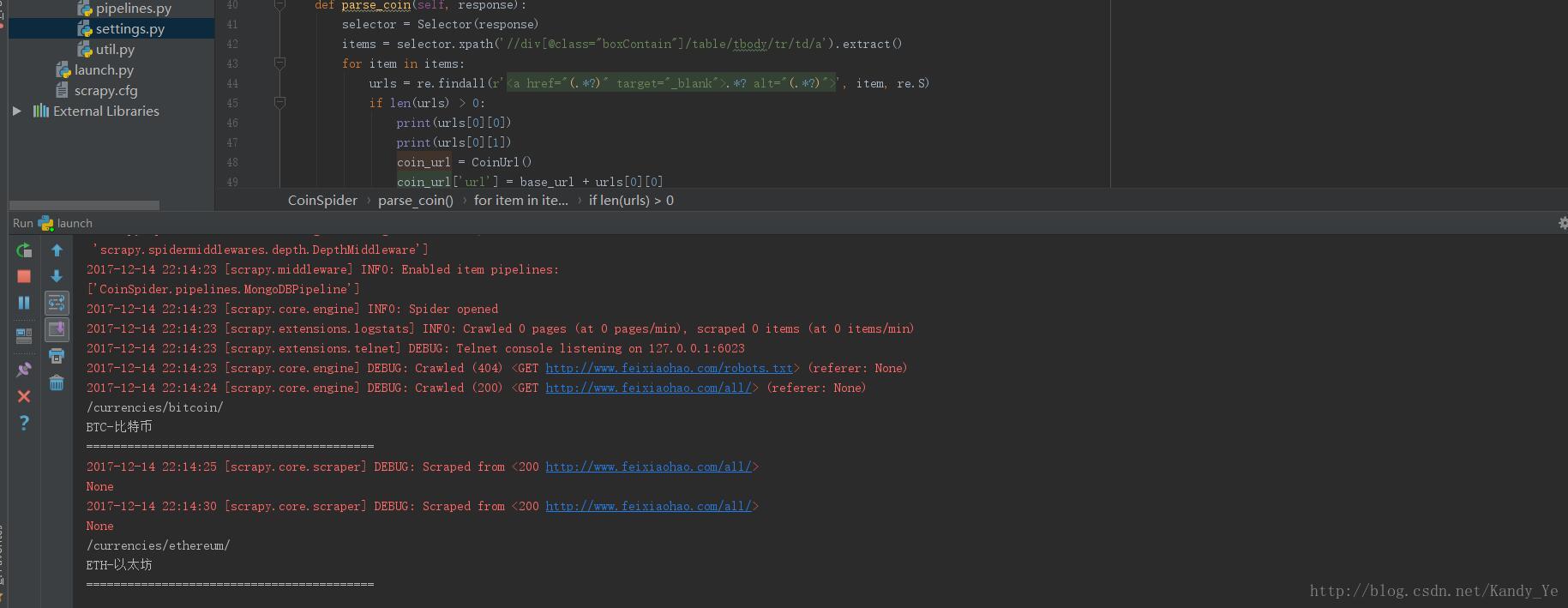
基本代码已经贴在文中了,写的比较乱。欢迎大家讨论。
部分数据截图: